Java 를 사용하여 백엔드 서버 개발을 하면 객체지향 설계를 한다.
DB 는 대부분 관계형 DB 를 사용한다.
따라서 이 둘을 모두 사용하려면 객체를 관계형 DB 에 저장해야 하고, SQL 로 관리해야 한다. 여기서 패러다임의 불일치가 발생하고, 이 과정에서 자바 객체를 SQL 로 바꾸거나 SQL을 자바 객체로 바꾸는 과정을 직접 코딩해줘야 한다.
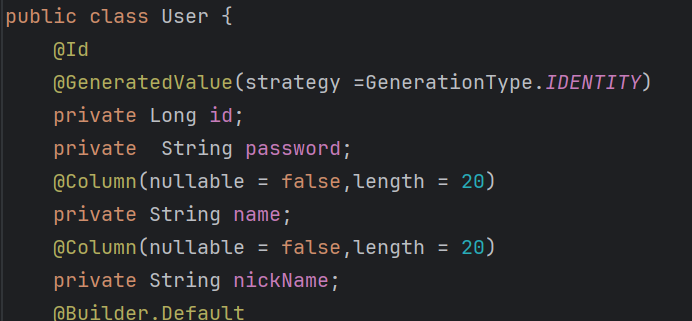

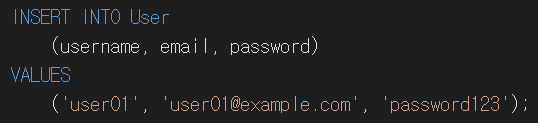
결론은 개발은 객체지향적으로 하지만 SQL에 의존하는 과정을 꼭 거쳐야 한다.
객체와 관계형 데이터 베이스
둘은 시발점 자체가 달라 패러다임의 불일치가 발생한다.
관계형 데이터 베이스의 목적은 데이터를 정규화 해서 무결성을 갖게 하는 것이고,
객체는 데이터랑 메서드를 잘 결합하여 캡슐화, 추상화, 정보선별, 상속, 다형성 등 변화에 유연하게 대 하기 위함이다.
- 캡슐화 (Encapsulation)
- 객체의 데이터(속성)와 그 데이터를 조작하는 메소드를 하나의 단위로 묶는 과정
- 데이터의 접근을 제한하고, 외부에서 직접적으로 접근하는 것을 막아 데이터의 무결성을 보장
- 캡슐화는 주로 접근 제어자(public, private 등)를 사용하여 구현.
- 추상화 (Abstraction)
- 복잡한 실제 상황에서 중요한 부분만을 간추려 내어 간단하게 표현하는 과정.
- 클래스를 설계할 때 필요한 속성과 메소드만을 정의하여 사용자에게 필요한 인터페이스만을 제공하여 관리
- 정보 선별 (Information Hiding)
- 객체의 세부 구현 내용을 숨기는 것
- 캡슐화의 한 부분으로 볼 수 있으며, 사용자가 객체를 사용할 때 내부 구현을 몰라도 사용할 수 있음.
- 프로그램의 유연성과 유지보수성을 높일 수 있음.
- 상속 (Inheritance)
- 한 클래스(부모 클래스)의 속성과 메소드를 다른 클래스(자식 클래스)가 받아 사용할 수 있게 하는 기능.
- 코드의 재사용성을 높이고, 중복을 줄이며, 계층적 분류를 가능하게 함.
- 다형성 (Polymorphism)
- 같은 이름의 속성이나 메소드가 다른 클래스에서 다양한 방식으로 동작할 수 있도록 하는 기능.
- 오버라이딩(Overriding)과 오버로딩(Overloading)은 다형성을 구현하는 대표적 방법.
- 다형성을 사용함으로써 프로그램이 더 유연해지고, 확장성이 높음.
엔티티와 테이블을 매핑하는 과정에 많은 시간이 소요되기 때문에, 일일이 쿼리로 전환하려면 주 업무에 해당하는 인력이 사용되어 비효율적이다.
객체와 관계형 데이터베이스의 차이
상속
엔티티의 경우

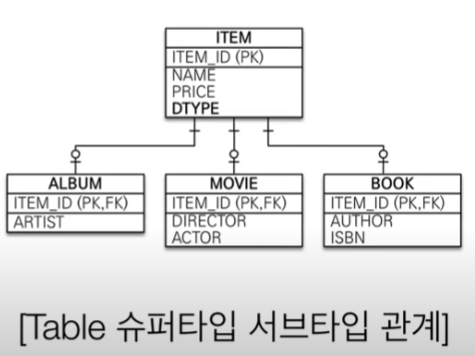
DB에서 상속을 유사하게 구현하려면, 일단 ITEM 테이블을 만들고, DTYPE 이라는 컬럼 (ALBUM 인지 MOVIE 인지 ... 구분 용도)를 만들고, 각각의 테이블에 필요한 컬럼을 만든 뒤, 같은 PK를 할당한 뒤 필요할 때 JOIN 하여 해결한다.
이 방식의 단점
item 하나 저장하거나 불러오는데 상속하는/받는 테이블 모두를 불러오거나 Insert 하고 해야해서 비효율적이고 복잡함.
연관관계
객체의 연관 관계
참조를 통해 구현.
예를 들어, User 객체가 다른 여러 User 객체를 팔로우할 수 있다면, User 클래스 내에 Follow 객체 리스트를 포함시킬 수 있음
class User {
private List<User> follows;
// 팔로우하는 사용자 추가
public void addFollow(User user) {
follows.add(user);
}
// 팔로우하는 사용자 목록 반환
public List<User> getFollows() {
return follows;
}
}

데이터베이스 테이블 관계
데이터베이스에서는 외래 키(Foreign Key)와 JOIN 연산을 사용하여 관계를 구현.
예를 들어, users 테이블과 follows 테이블에서 follows 테이블은 follower_id와 followed_id 두 개의 필드를 가지며, 두 필드 모두 users 테이블의 id를 참조한다.
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100)
);
CREATE TABLE follows (
follower_id INT,
followed_id INT,
FOREIGN KEY (follower_id) REFERENCES users(id),
FOREIGN KEY (followed_id) REFERENCES users(id)
);
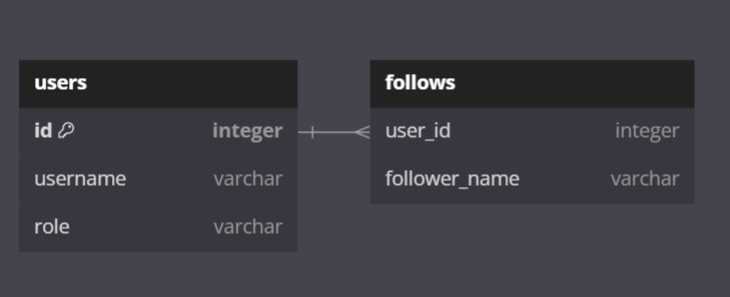
발생할 수 있는 복잡성
- 반복적인 쿼리 작성: get 메서드에서 매번 SQL 쿼리를 작성해야 하며, 이는 코드 중복과 유지 보수의 어려움을 초래
- 일관성 유지: 다양한 상황에서 get 메서드를 사용할 때, 동일한 결과를 보장하기 위해 일관된 방식으로 쿼리를 작성 해야 함. 개발자 간의 협업에서 불쾌함을 일으킬 수 있는 요소.
- 복잡한 연관 관계: 한 객체가 여러 다른 엔티티와 복잡한 연관 관계를 가지고 있을 때, 이를 관리하기 위한 다양한 get 메서드를 작성해야 함. 예를 들어, 사용자가 팔로우하는 사용자의 게시물을 가져오는 경우, users, follows, posts 테이블 간의 복잡한 JOIN 쿼리가 필요할 수 있음.
이러한 복잡성을 해결하기 위해 ORM 라이브러리(예: Hibernate, JPA, Sequelize 등)를 사용하면, ORM은 객체와 데이터베이스 테이블 간의 매핑을 자동으로 처리해줌으로써, 개발자가 SQL 쿼리 대신 객체 지향적인 방식으로 데이터를 관리할 수 있게 해준다. ORM을 사용하면 코드 중복을 줄이고, 개발 생산성을 향상시키며, 데이터 접근의 일관성을 유지할 수 있다.
'[프로그래밍] JPA' 카테고리의 다른 글
| [JPA] JPA의 기본 키 생성 전략 (0) | 2024.05.04 |
|---|---|
| [JPA] Entity Mapping (0) | 2024.05.04 |
| [JPA] JPA의 영속성 컨텍스트 (0) | 2024.05.03 |
| [JPA] JPA 와 DB Dialect (0) | 2024.05.01 |
| [JPA] JPA? (0) | 2024.04.29 |